the judgment premium
2026-03-04
last month, a public servant posted on reddit that he'd vibecoded an entire government SaaS platform. zero budget, zero engineering team, zero prior coding experience. the app worked. it passed internal review. it was about to be deployed to production.
his question to the community wasn't about features. it was: "how do I know if this is actually safe?"
nobody could answer him. not because the question was hard, but because answering it requires the one thing AI can't generate: the ability to look at working software and know whether it should be trusted.
the thing nobody talks about
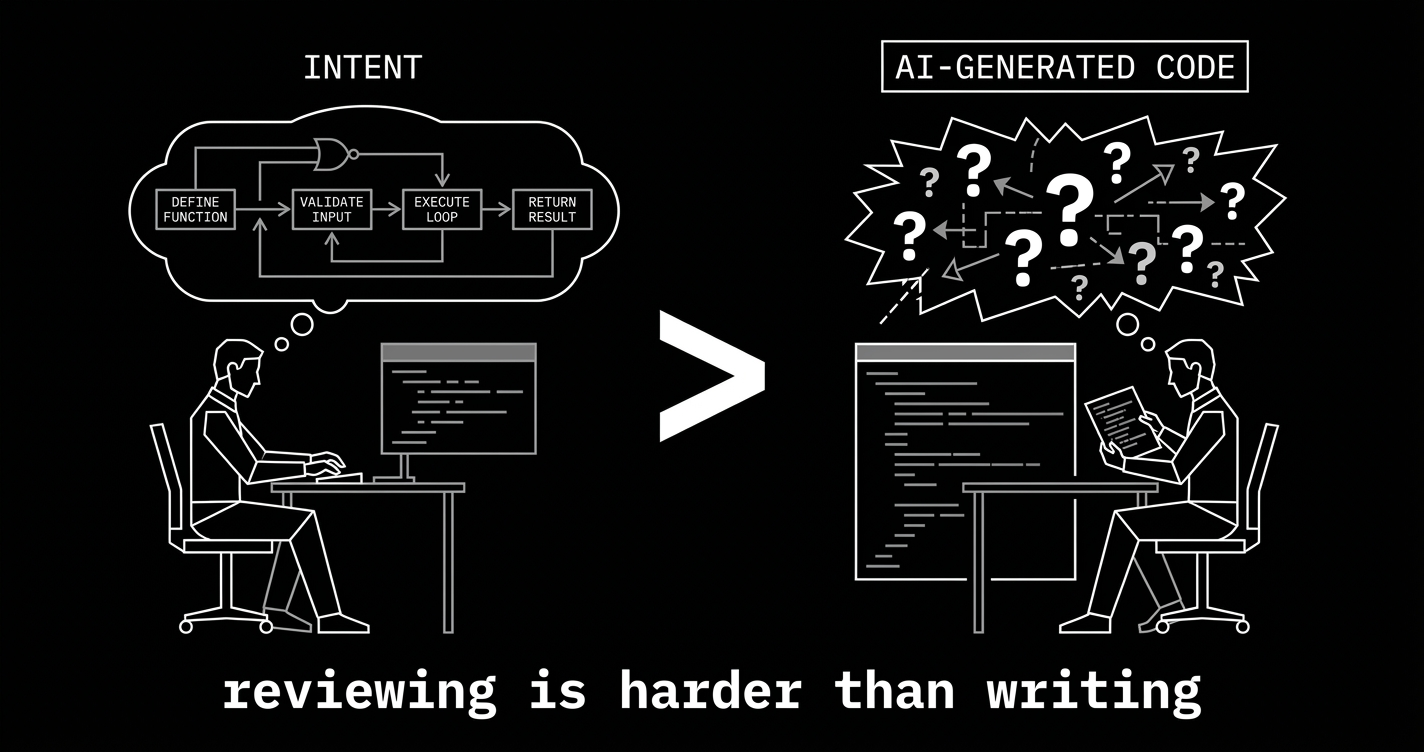
here's the uncomfortable truth buried under every AI productivity stat: reviewing AI-generated code is harder than writing code from scratch.
think about that. not "slightly different." harder.
when you write code yourself, every decision is conscious. you know why the auth check happens before the database call because you put it there. you know the error handler exists because you considered what happens when the connection drops. the mental model builds as you build. intent and implementation stay in sync.
AI-generated code has no intent. it has output. and the person reviewing it has to reverse-engineer why the code is the way it is, whether the approach is right for this specific context, and what might go wrong under conditions the model never considered — all while the code presents itself with the same confidence whether it's flawless or catastrophically wrong.
the model that writes perfect authentication middleware uses exactly the same tone as the model that introduces a session fixation vulnerability. there is no hesitation. no "I'm not sure about this part." no yellow flag. the output is uniformly confident. your ability to override that confidence is the only thing standing between working software and a breach.
and here's where it gets structural: vibecoding was designed for people who don't write code. reviewing code requires that you can. the value proposition contains its own contradiction.
two sets of numbers that can't both be true (but are)
the adoption numbers are staggering. claude code hit $2.5 billion in annualized revenue by early 2026, doubling since the start of the year. the pragmatic engineer's survey this week put claude code as the most loved developer tool at 46% — cursor at 19%, copilot at 9%. karpathy said last week that programming has become "unrecognizable." nobody disputes that AI coding tools work. they obviously work.
now the other numbers.
veracode's 2025 report: 45% of AI-generated code contains security flaws. aikido security's 2026 report: AI-generated code now causes one in five breaches. coderabbit's research: 1.7x more logical bugs compared to traditional development. gitclear's analysis of 153 million lines of code: code churn — lines rewritten within two weeks — nearly doubled from its pre-AI baseline, with a 4x increase in duplicated code.
a four-person backend team profiled by altersquare discovered 47 subtle production bugs over six months. not syntax errors. logical mistakes — the kind that pass every test and detonate when a real user does something the model didn't expect.
AI coding tools are simultaneously the most loved developer tools and the largest source of new production bugs. both statements are supported by data. both are true right now, today. and nobody has a plan for resolving the contradiction, because the contradiction is the product.
the cost of building without knowing
before AI, bad judgment was naturally throttled by the cost of implementation. you couldn't build ten wrong things because you could barely afford to build one. the expense of building was, accidentally, a filter. if it took six months to build a feature, someone senior had to approve it first. that approval was a judgment checkpoint disguised as a resource allocation decision.
that filter is gone now.
you can build ten wrong things before lunch. the government SaaS guy built an entire platform. his problem wasn't capability — it was not knowing which of the things he built would cause a security incident. and he had no way to find out, because finding out requires the exact expertise that AI promised he wouldn't need.
this is playing out at every level. the junior developer who accepts 80% of copilot suggestions without modification — what's their rejection criteria? the startup founder who vibecoded an MVP and is now taking on paying customers — what happens when the payment flow breaks for a currency with three decimal places? the engineering manager who sees PR velocity triple and calls it a win — who is checking whether those PRs introduced the next outage?
the answer, in most cases, is nobody. not because people are negligent, but because the tooling created a situation where more output requires more evaluation, and nobody budgeted for the evaluation.
gitclear's finding about code duplication makes this concrete. the 4x increase means AI tools are copying patterns without understanding whether those patterns apply. they're generating code that looks right because it matches the training data, not because it's correct for the specific situation. that's a system without judgment — it can't distinguish between "this pattern worked somewhere" and "this pattern works here." every time a developer accepts that code without catching the distinction, they're inheriting a decision they didn't make and don't fully understand.
the people who are about to find out
every technology shift has winners and losers. the AI discourse focuses almost entirely on who wins. here's who loses.

the mid-level developer who thinks seniority is years served. five years of experience shipping CRUD apps doesn't prepare you for evaluating whether an AI agent's database migration strategy will corrupt production data. seniority that was earned by doing the same work for longer is worth zero in a world where AI does that same work for free. the judgment premium only applies to judgment that was earned through genuine consequence — operating systems under load, debugging outages at 3 AM, making architectural calls that aged well or badly. time-in-seat doesn't count.
the manager who measures output volume. lines of code, tickets closed, PRs merged — AI can inflate all of them trivially. the engineering manager who reports 3x velocity to the VP without mentioning that production incidents also tripled is building a case study in how not to manage AI-assisted teams. when the bill comes due — and it always comes due, usually as a security incident or a system that can't be modified without rewriting — the velocity numbers won't help.
the vibecoder who doesn't know what they don't know. this is the hardest one, because these people are genuinely excited about what they've built. the government SaaS guy wasn't reckless. he was proud, and reasonably so. he built something real with no background. but his reddit post was a cry for help disguised as a success story, and the gap between "I built this" and "I can evaluate this" is exactly where serious consequences live. the cruelest thing about AI-generated code is that it looks professional. it follows conventions. it passes linters. it has proper error handling. it looks exactly like code written by someone who knows what they're doing — which makes it nearly impossible for someone who doesn't to spot the places where it's wrong.
the market is already pricing this in
you can see the premium forming if you know where to look.
the companies that are winning with AI aren't the ones shipping the most code. they're the ones with the most experienced reviewers. they have senior engineers whose job shifted from writing code to evaluating code — and they're paying those people more, not less, because the evaluation skill is harder than the writing skill ever was.
the startups that survive the vibecoding wave won't be the ones that built the fastest. they'll be the ones where someone on the team could actually tell the difference between code that works and code that's correct. "works" means it runs. "correct" means it runs when the timezone is UTC+5:45, the user's session token expired mid-transaction, and the payment provider returns an error in a format that changed since the API docs were last updated.
the hiring market is starting to reflect this. the interview that tests "can you build this?" is becoming irrelevant — AI can build it. the interview that tests "here's a system an agent built overnight, find the three things wrong with it" is where the premium lives. the candidates who can do that are the ones who've earned their judgment through production experience. and there aren't enough of them, because judgment accumulates at the speed of human experience, not at the speed of inference.
this is the structural reason the judgment premium persists: you can't generate 10x more judgment by spending 10x more on compute. you can't train it in a bootcamp. you can't prompt-engineer your way to it. judgment comes from consequences — from being the person responsible when the system breaks, from making the call that turned out wrong and learning why, from watching the elegant architecture collapse at scale and understanding what you missed. every year of that experience compounds. there's no shortcut, and there's no API.
the question
karpathy was right that vibecoding works for throwaway weekend projects. the part everyone ignored is that he explicitly said "throwaway." most software isn't.
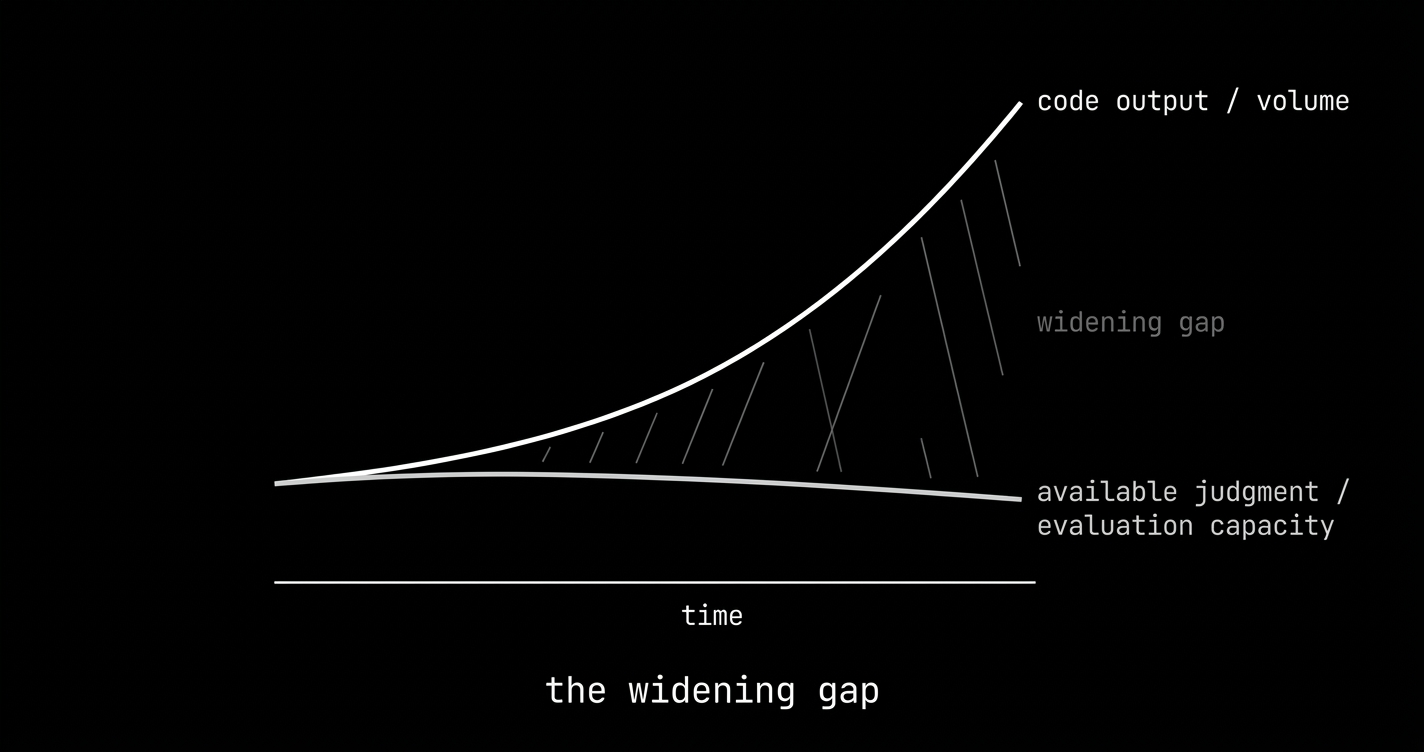
the government SaaS, the payment flow, the authentication layer, the medical record system — these are things with consequences. the people building them with AI are getting faster every quarter. the people who can evaluate whether they got it right are not getting more numerous.
the gap between those two curves is the judgment premium. it's widening.
here's the question the article is actually about, the one the government SaaS guy posted on reddit and nobody could answer:
you built the thing. it works. it's in production.
how do you know it's right?
and if you can't answer that — who can? and what are they worth to you?