the great absorption
2026-02-26
in november 2025, cursor crossed $1 billion in annual recurring revenue. one million developers used it daily. the company was valued at $29.3 billion. four months later, anthropic shipped claude code — a terminal-native coding agent that does most of what cursor does, without the IDE wrapper, at API cost.
that's the story of this entire layer. build something impressive, watch the platform ship it natively, scramble for what's left.
this week it happened twice. cursor launched cloud agents — autonomous VMs that write, test, and ship code. perplexity launched computer — a multi-model orchestrator that delegates tasks across claude, gemini, grok, and gpt. both products are genuinely good. both companies are building on sand.
the platform trap, accelerated
every major technology cycle follows the same script. an application layer company identifies a user need, builds a product around it, and validates the market. the platform watches, learns, and absorbs.
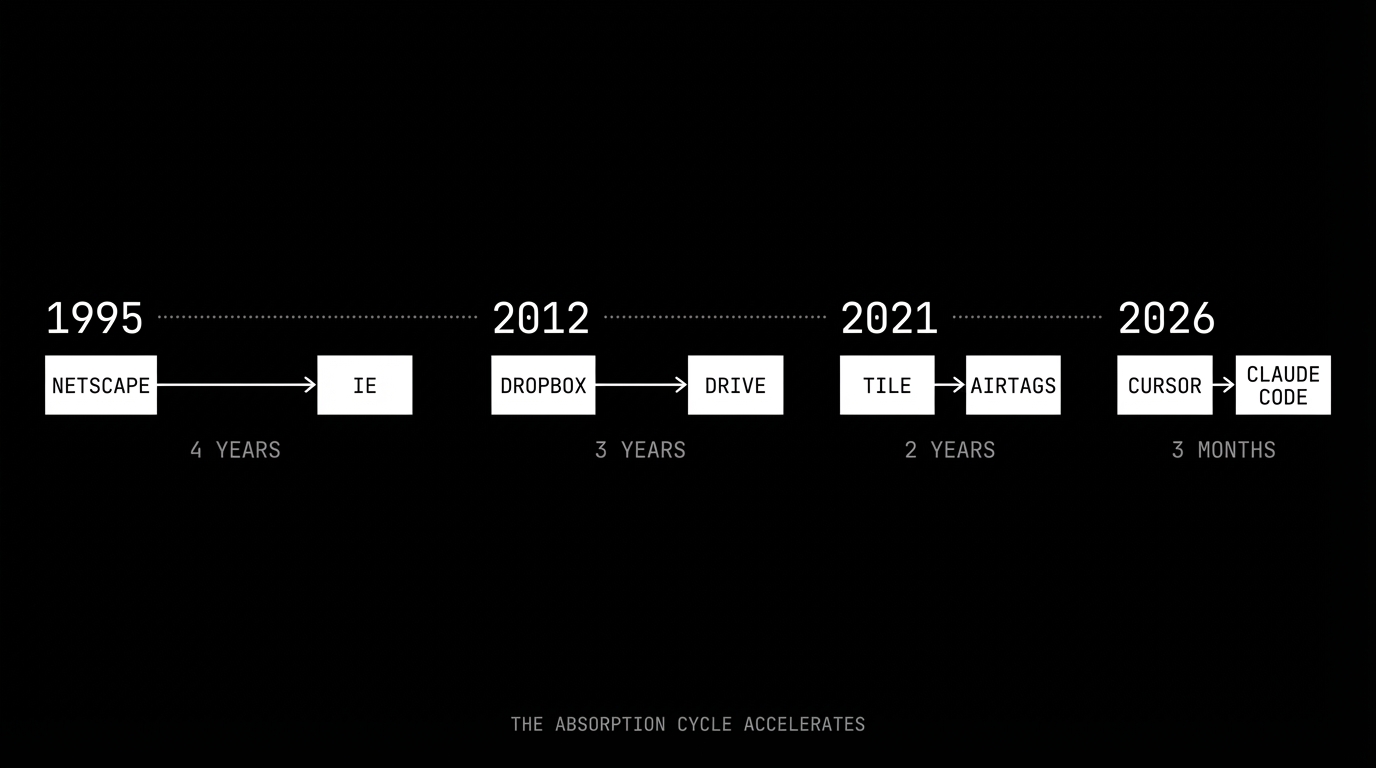
microsoft did it to netscape. the browser was the most important application of the early internet, and microsoft shipped internet explorer bundled with windows. it took four years. google did it to dropbox. cloud storage was the killer app for file management, and google shipped drive integrated into every google account. three years. apple did it to tile. location tracking was a proven consumer category, and apple shipped airtags with the find my network built in. two years.
in AI, the cycle has compressed to months. cursor shipped background agents on february 12. anthropic already has claude code. openai already has codex. the window between "innovative feature" and "native platform capability" used to be measured in years. now it's measured in quarters.
the compression isn't accidental. it happens because the platform layer and the application layer use the same foundation: the model. when cursor builds an agent, it builds on claude. when anthropic wants that same capability, it doesn't need to reverse-engineer anything — it already has the model, the training data, and the interaction logs from every API call cursor makes.
the dependency inversion
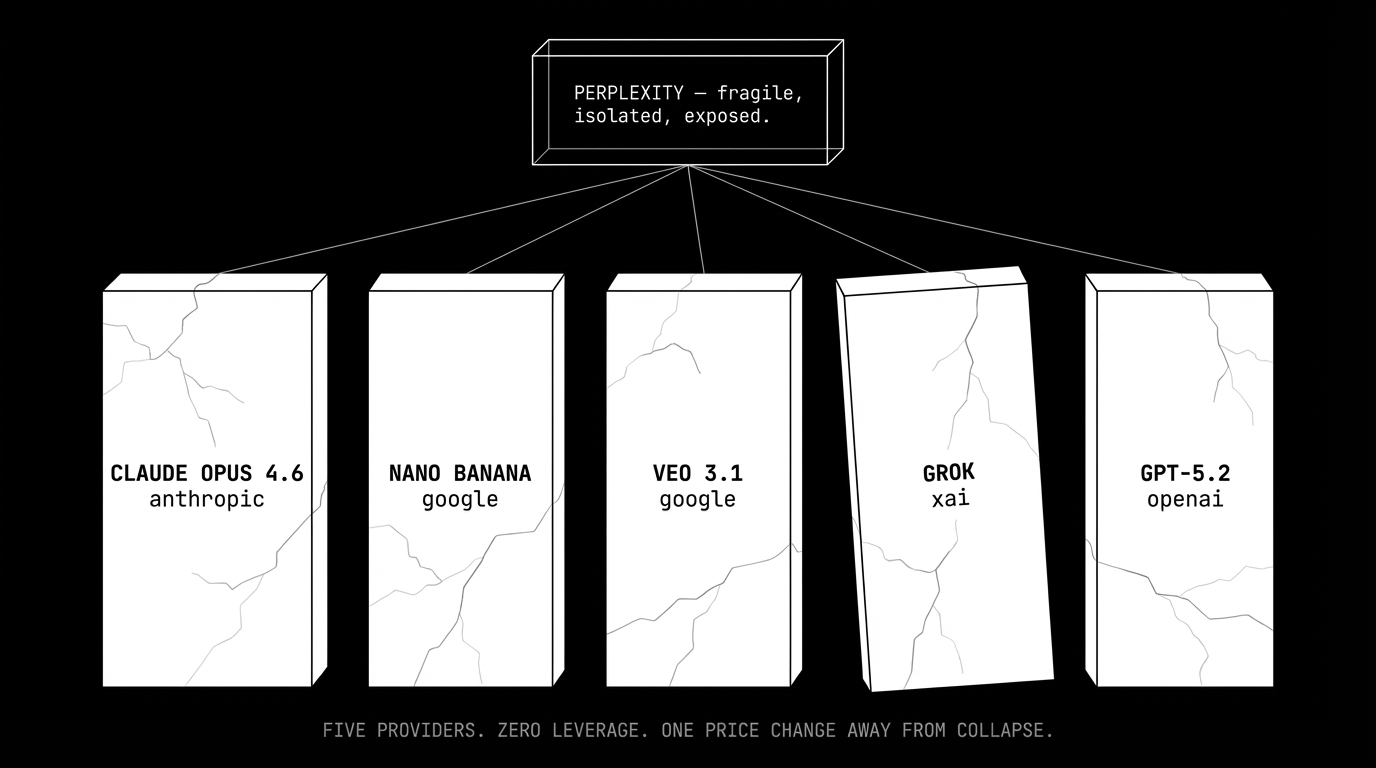
perplexity's architecture makes this dynamic explicit. their product routes tasks across five different model providers:
- core reasoning: claude opus 4.6 (anthropic)
- image generation: nano banana (google)
- video: veo 3.1 (google)
- search: grok (xai)
- long-context: gpt-5.2 (openai)
this looks like smart engineering. use the best model for each task. but look at it from the other direction: their product quality is entirely determined by decisions made in five different companies' roadmap meetings — none of which they attend. every model improvement makes perplexity temporarily better. every API pricing change, rate limit adjustment, or terms of service update is an existential threat they cannot predict or prevent.
this isn't a supply chain in any traditional sense. supply chains have contracts, alternatives, and switching costs that protect the buyer. what perplexity has is dependency with zero leverage. anthropic could ship a competing orchestrator tomorrow with preferential API access, lower latency, and better rate limits. there is nothing in perplexity's architecture that prevents this.
at $200M ARR and a $20 billion valuation, perplexity trades at roughly 100x revenue. that multiple assumes years of continued growth at near-current rates. it also assumes that none of their five model providers decide to compete with them directly. that assumption is getting harder to defend by the week.
game theory: the provider's dilemma
from anthropic's perspective, the optimal strategy is clear but timing-dependent.
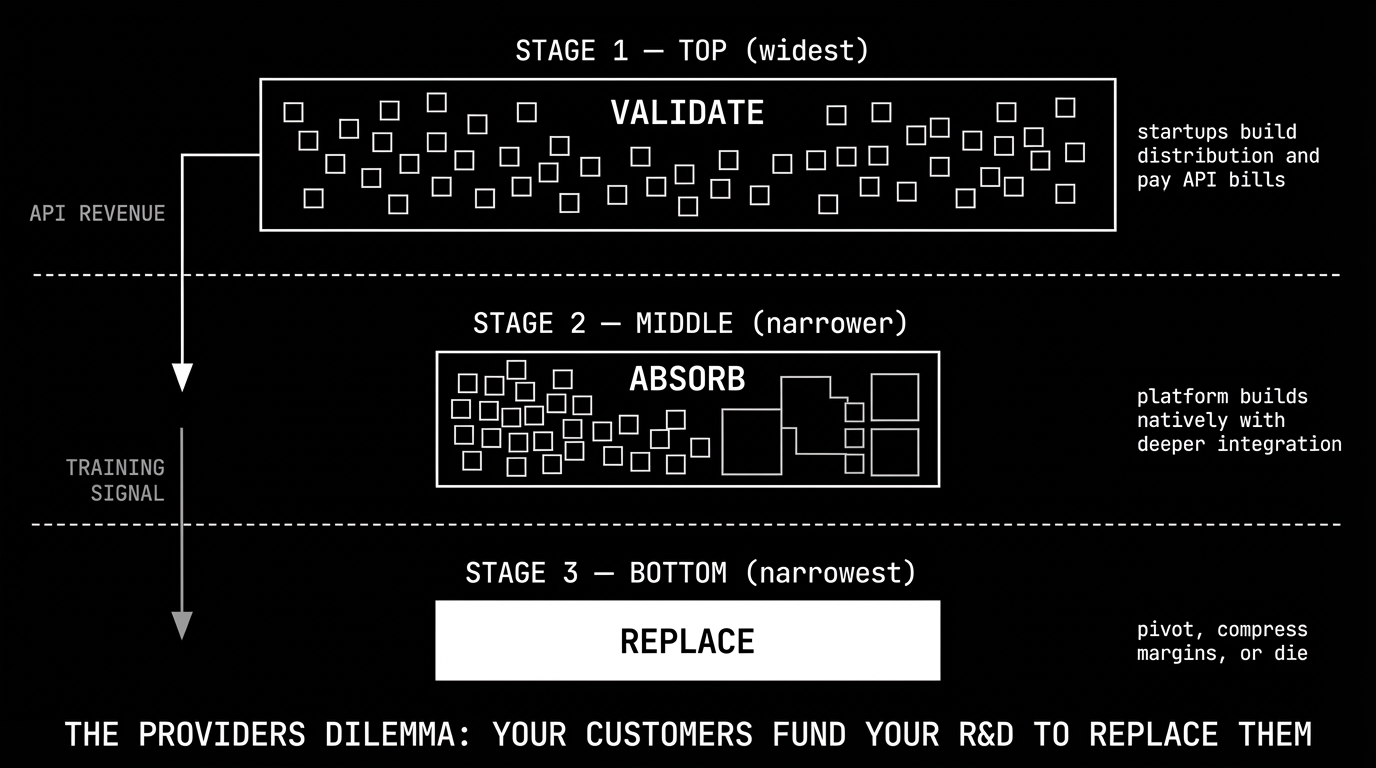
phase 1: let the application layer validate. cursor, perplexity, replit, and hundreds of smaller companies build products, acquire users, and generate revenue — all while paying API bills to the model providers. they're doing free market research. every API call teaches anthropic what users want, how they use agents, and where the friction points are.
phase 2: build it natively. take the validated features and ship them with deeper model integration, lower latency, and tighter feedback loops than any API consumer can achieve. claude code doesn't need to call an API — it is the API.
phase 3: the squeeze. the application layer either pivots to something genuinely defensible, accepts margin compression as a commodity reseller, or dies.
the funding mechanism is what makes this particularly brutal. phase 1 companies are paying for phase 2 through their API bills. CNBC reported this week that claude code has grown to over $2.5 billion in run-rate revenue — more than cursor's entire ARR. that revenue was built on the back of what cursor's million daily users taught anthropic about developer behavior. every prompt, every edit, every agent loop is a training signal flowing upstream to the company building cursor's replacement.
and the platforms aren't waiting patiently. openai's codex has already surpassed 1.5 million weekly active users. github copilot is embedded in the world's most popular code editor. this isn't phase 2 anymore. we're already in phase 3.
the steelman: why they might survive
to be fair, there are real arguments for cursor and perplexity's durability.
cursor has distribution and habit. a million daily active developers don't switch tools easily. the IDE is where developers live — it's not just a feature, it's an environment. cursor's advantage isn't any single capability; it's the integrated experience of code editing, chat, and agent execution in one place. terminal tools and VS Code extensions don't replicate that seamlessly yet.
perplexity has brand and search behavior. 45 million monthly active users come to perplexity for answers, not for a chatbot. the search habit is sticky. google's search monopoly lasted decades partly because people don't change where they type questions. perplexity could own that same muscle memory for AI-native search.
multi-model orchestration might have lasting value. if models don't converge — if claude stays best at reasoning while grok stays best at real-time data — then the orchestration layer retains value as a routing intelligence. convergence is happening fast, but it isn't guaranteed.
these are real strengths. the question is whether they're enough to survive platform absorption. netscape had distribution too — 80% browser market share in 1996. within four years it was gone. dropbox had 500 million registered users when google drive launched. tile owned the location tracker category for seven years before airtags. distribution delays absorption. it has never prevented it.
second-order effects
if the application layer compresses — and the evidence suggests it will — the consequences extend well beyond cursor and perplexity.
the talent flywheel has already started spinning. in the past six months, anthropic has hired senior engineers from adept, inflection, and character.ai — all application layer companies that struggled to compete with the platforms. as more app layer companies hit the margin squeeze, their best people leave for the places with the most leverage: the foundation model labs. this creates a compounding problem. better talent at the platform layer accelerates the capability gap, which makes the application layer less attractive, which pushes more talent toward the platforms. anthropic, openai, and google don't need to outbid the startups. they just need to wait.
the write-down clock is ticking. cursor's $29.3 billion valuation and perplexity's $20 billion valuation both price in a world where the platform layer stays dumb. investors who funded these rounds at 30x and 100x revenue will need to explain, within 18 months, why the platform's native offering isn't eating their portfolio company's growth. the next AI funding cycle will look fundamentally different — money will flow to either foundation models themselves, or to vertical applications with proprietary data moats that platforms genuinely can't replicate. "orchestration" as a standalone value proposition is dead.
open source is becoming the default benchmark. when zdnet reviewed perplexity's computer, they didn't compare it to cursor or copilot. they framed it as "a safer openclaw" — the comparison point was the free, open source alternative. this is a structural shift. when the benchmark is a product that costs zero, every commercial wrapper in the middle has to justify its margin against free. you can't acquire free. you can't undercut zero. as the commercial middle layer gets squeezed from above by platforms and from below by open source, the viable territory shrinks to almost nothing.
enterprises are already cutting out the middle. large organizations that started with cursor licenses or perplexity subscriptions are renegotiating. why pay for a translation layer when you can contract directly with anthropic for API access and build your own thin integration? the lock-in was never with the application — it was always with the model. companies like stripe, shopify, and notion have already built direct integrations with anthropic and openai APIs, bypassing the application layer entirely.
model convergence is killing the multi-model thesis. perplexity's bet is that routing between specialized models creates durable value. but the gap between frontier models is narrowing every quarter. claude 4.6 can now handle real-time data tasks that used to require grok. gemini 3 pro generates images that compete with dedicated image models. when one model handles 95% of your use cases, the engineering complexity of maintaining five provider integrations isn't worth the marginal 5% improvement. multi-model orchestration is an artifact of early 2026 — a moment where models had distinct, complementary strengths. that moment is ending faster than perplexity's roadmap assumes.
what survives
three positions are structurally durable.
own the model. anthropic, openai, google, meta. you can't be disintermediated if you are the intermediary. the model is the platform. every capability the application layer builds on top of your model is a capability you can eventually offer natively, with better integration and lower latency. this is the most defensible position in AI, and it's why these companies are valued in the hundreds of billions.
own distribution that models can't replicate. apple has the device. google has the search box. slack has the workplace graph. these companies can integrate AI without being absorbed by it because their moat isn't the AI — it's the surface area where users already live. the AI is a feature, not the product. that's the key distinction. when apple ships on-device AI, it's adding capability to a billion existing devices. when cursor ships AI, the AI is the device. one is additive. the other is exposed.
be free — but understand what that means. open source survives platform consolidation, but not for the romantic reason people think. it survives because it serves a different market: users who value sovereignty over convenience, and companies that can't afford or won't accept platform lock-in. openclaw, ollama, and open-weight models don't compete with anthropic on capability. they compete on control. the nuance that most open source advocates miss is that meta and google release open weights strategically — llama and gemma exist to commoditize the model layer and weaken openai's pricing power, not out of altruism. open source in AI is partly a genuine community movement and partly a weapon in the platform war. both can be true. the result is the same: a capability floor that no commercial wrapper can price below. open source doesn't need to be the best. it needs to be good enough and free. that combination outlasts every funding cycle.
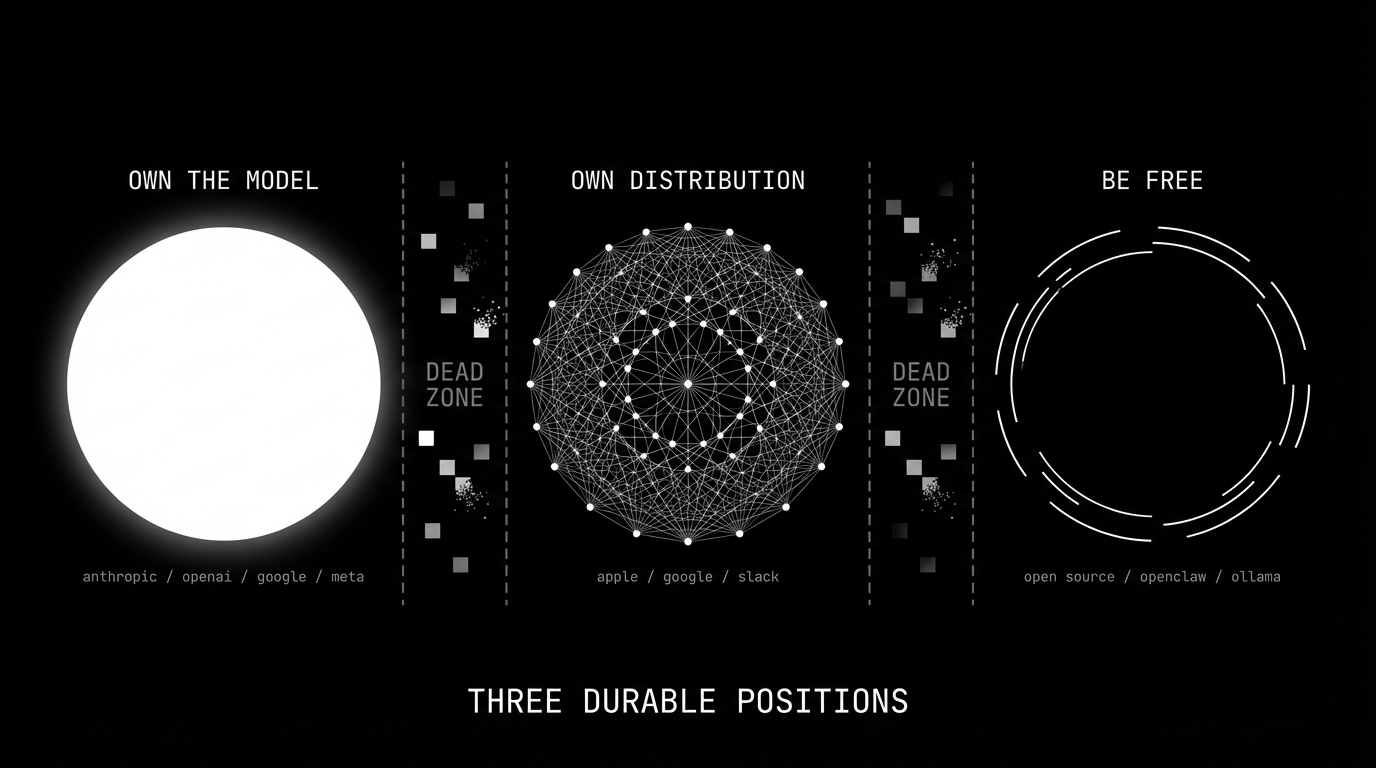
everything in between — every company whose pitch is "we're the best way to use someone else's model" — is in the dead zone. they're not building products. they're building demos for features their providers will ship natively.
what to do about it
if you're building in the application layer right now, you have three realistic options.
go vertical. find a domain where you can accumulate proprietary data that the platform can't replicate. a legal AI trained on case law, a medical AI integrated with hospital EHR systems, a financial AI with real-time market data feeds. the platform can absorb the general capability, but it can't absorb your data moat. harvey (legal) and abridge (medical) are early examples of companies that understood this — their value isn't in the model, it's in the domain-specific data pipeline that makes the model useful for a specific workflow.
go infrastructure. build the picks and shovels — observability, evaluation, deployment, security. the platform layer needs tooling that isn't core to their model business. this is the harrison chase playbook: langchain the framework was vulnerable to absorption, but langsmith the observability platform serves every model provider equally. the infrastructure play works because it's orthogonal to the model — it doesn't depend on which model wins, it depends on all of them needing to be monitored, tested, and deployed.
go open source. if you can't beat the platform on integration and you can't beat them on price, make the price zero and win on community. the open source play doesn't generate revenue from the tool itself — it generates reputation, hiring leverage, consulting revenue, and an ecosystem that the platform can't easily replicate. vercel built a business on top of next.js. hashicorp built a business on top of terraform. the tool is free. the value capture happens at the edges.
what you can't do is stay in the middle. the middle is where cursor and perplexity live today: better than the platform's native offering, but not by enough, and not for long enough.
the uncomfortable question
if anthropic ships a native multi-model orchestrator — and they will, because the data from their API shows users want it — what is perplexity?
if openai ships cloud sandboxes for autonomous code agents — and they will, because cursor just proved the market — what is cursor?
the answer, in both cases, is a company with a shrinking feature advantage, an expensive API bill that funds their competitor's R&D, and a cap table full of investors who priced in a world where the platform layer stayed dumb.
what this means
the great absorption isn't a prediction. it's a pattern that has already started executing. the interesting question isn't whether it will happen — it's what comes after.
the optimistic read: the application layer was always a transitional phase. it existed to explore the solution space, to figure out what users want from AI, and to train the platforms on what to build. that phase is ending. what replaces it is a world where AI capability is abundant and cheap, provided directly by the model companies and the open source community. the value shifts from "access to AI" to "what you do with AI" — domain expertise, proprietary data, unique workflows.
the pessimistic read: we're watching the fastest concentration of power in technology history. three or four companies will control the foundational layer of every AI application. the application layer — the part of the stack where startups were supposed to thrive — is being absorbed before it can mature. the VC ecosystem that funded it will take massive losses. the engineers who built it will be absorbed too, into the same companies that killed their employers.
the realistic read is probably somewhere in between. the horizontal application layer — the cursors and perplexities — compresses. the vertical application layer — companies with real domain expertise and proprietary data — thrives. open source provides the escape valve for everyone who doesn't want to be locked in. and the platforms become what platforms always become: the infrastructure that everything else is built on.
this week, cursor and perplexity both shipped impressive products. both are already obsolete — not because they're bad, but because the companies they depend on are building the same thing, faster, cheaper, and closer to the metal.
the platform layer isn't staying dumb. it never was.