cheap enough to be wrong
2026-03-04
in january 2026, a senior engineer at a series B startup told me something that stuck: "we shipped more in the last three months than in the previous two years. I have no idea how half of it works."
he wasn't complaining. he was describing the new normal. his team of eight had adopted claude code in october. by december, their deployment frequency had tripled. features that used to take a sprint now took a day. the board was thrilled. the metrics were spectacular.
then he said the thing that mattered: "I approved PRs last week where I understood maybe 60% of the code. I used to understand 95%. nobody's tracking that number."
nobody is tracking that number. that's the article.
a new kind of debt
technical debt is a term every engineer knows. it's the code you wrote quickly, knowing you'd fix it later. the shortcut, the hack, the TODO comment that's been there since 2019. technical debt is visible — you know it's there, you can point at it, you can estimate the cost of paying it down.
there's a new kind of debt accumulating in AI-assisted codebases, and it's worse than technical debt because it's invisible.
margaret storey, a computer science professor at the university of victoria, published an essay in february 2026 that named it: cognitive debt. the essay was shared by simon willison and cited by martin fowler — two of the most respected voices in software engineering — because it articulated something teams were experiencing but couldn't describe.
cognitive debt is the gap between the code that exists and the team's understanding of that code. technical debt is code you know is bad. cognitive debt is code you don't understand well enough to know whether it's bad.
storey described teams that had shipped significant features using AI assistance and then tried to modify those features months later. the code wasn't broken — it passed tests, it handled errors, it followed conventions. the problem was that nobody on the team could confidently predict what would happen if they changed it. the shared understanding of the system — the mental model that lets a team reason about their software — had fragmented. they could generate new code faster than ever. they could no longer explain what their existing code did.
the distinction sounds academic. it isn't. when you have technical debt, you can make a plan: refactor this module, rewrite that service, allocate two sprints. when you have cognitive debt, you can't even make a plan, because you don't know what you don't know. the code might be fine. it might be a time bomb. the fact that you can't tell the difference is the debt.
how it accumulates
every AI coding session borrows understanding from the future.
session one: you prompt the agent to build an auth module. it generates 400 lines of working code. you review it — most of it looks reasonable, some of it you don't fully follow, but it works. you ship it. your understanding of the auth module: maybe 70%.
session two: you ask the agent to add role-based access control. the agent reads its own code from session one and extends it. you review the changes. but the changes build on the 30% from session one that you didn't fully understand. your understanding of the RBAC layer: maybe 50%. your understanding of how it interacts with the original auth: maybe 40%.
session three: the token rotation logic needs to change. the agent modifies code from session one based on assumptions from session two. you review the diff. the diff looks clean. the implications of the diff, given everything underneath it, are unclear. your understanding: maybe 30% and dropping.
by session ten, the codebase works — it passes tests, it handles the happy paths, it does roughly what the specs describe. but the team's ability to reason about it has degraded to the point where every modification is a gamble. not because the code is bad. because the mental model that would let you evaluate the code never got built.
this is structurally different from traditional technical debt. with human-written code, the understanding builds as the code builds. the developer who wrote the auth module knows why every line is there, because they put it there. the understanding and the code were created simultaneously. with AI-assisted code, the code is created in seconds and the understanding... isn't created at all. or is created partially. or is created and then lost when the developer moves on to the next prompt.
the 91% increase in PR review time that faros AI documented across 10,000 developers isn't just a bottleneck problem. it's a symptom: developers are spending more time reviewing because they understand less. the review isn't getting harder because the code is worse. it's getting harder because the reviewer didn't write it, the author doesn't remember it, and the system it fits into was designed by a process that nobody fully witnessed.
the ponzi dynamics
the word "ponzi" sounds dramatic. it's also precise.
in a ponzi scheme, early investors get paid with money from later investors. the returns are real — you actually get your check. the scheme works until the rate of new investment can't cover the obligations to existing investors. then it collapses, and the total losses exceed what anyone expected because the accounting never reflected the true liabilities.
AI-assisted development has the same structure. each session's productivity is real — the features get built, the code gets shipped, the metrics go up. but each session's productivity is partly borrowed from the future. the understanding that should have been built alongside the code wasn't. that missing understanding is an obligation — a liability that will come due when the code needs to be modified, debugged, secured, or explained.
the returns look spectacular early on. the first five sessions are magical. features appear in hours. the demo impresses the board. the launch timeline accelerates. all real. all happening.
by session twenty, the team is spending more time providing context to the agent than the agent spends coding. the agent doesn't remember session twelve. the developer who ran session twelve left the company. the code from session twelve is in production, handling payments, and nobody can explain exactly why the retry logic works the way it does.
by session fifty, someone suggests rewriting from scratch, because modification has become more expensive than regeneration. this is the moment the ponzi dynamics become visible: the cumulative productivity gains were real, but they were offset by a cumulative loss of understanding that nobody measured.

gitclear's analysis of 153 million lines of code makes this visible at scale. code churn — lines rewritten within two weeks of being authored — nearly doubled from pre-AI baselines. code duplication increased 4x. these aren't quality metrics. they're cognitive debt metrics. code that gets rewritten within two weeks was never understood well enough to be written correctly the first time. code that gets duplicated was never understood well enough to be reused.
the ratchet
in theory, the market should correct this. companies that accumulate too much cognitive debt should lose to companies that maintain understanding of their systems. quality should win in the long run.
in practice, the feedback loops work against correction.
the feedback loop between shipping speed and market position is measured in weeks. the company that launches first gets the press, the users, the signal. the feedback loop between cognitive debt and consequences is measured in months to years. the auth bug doesn't cause churn. the memory leak doesn't show up in NPS. the fragile payment flow fails for 0.3% of transactions — not enough for most users to notice.
this creates a one-directional ratchet. each competitive cycle pushes quality standards down, because the cost of being slow is immediate and visible while the cost of not understanding your own software is delayed and diffuse. the company that takes six months to build something it fully understands competes against a company that took two weeks to build something that mostly works. "mostly works" wins round one. every time.
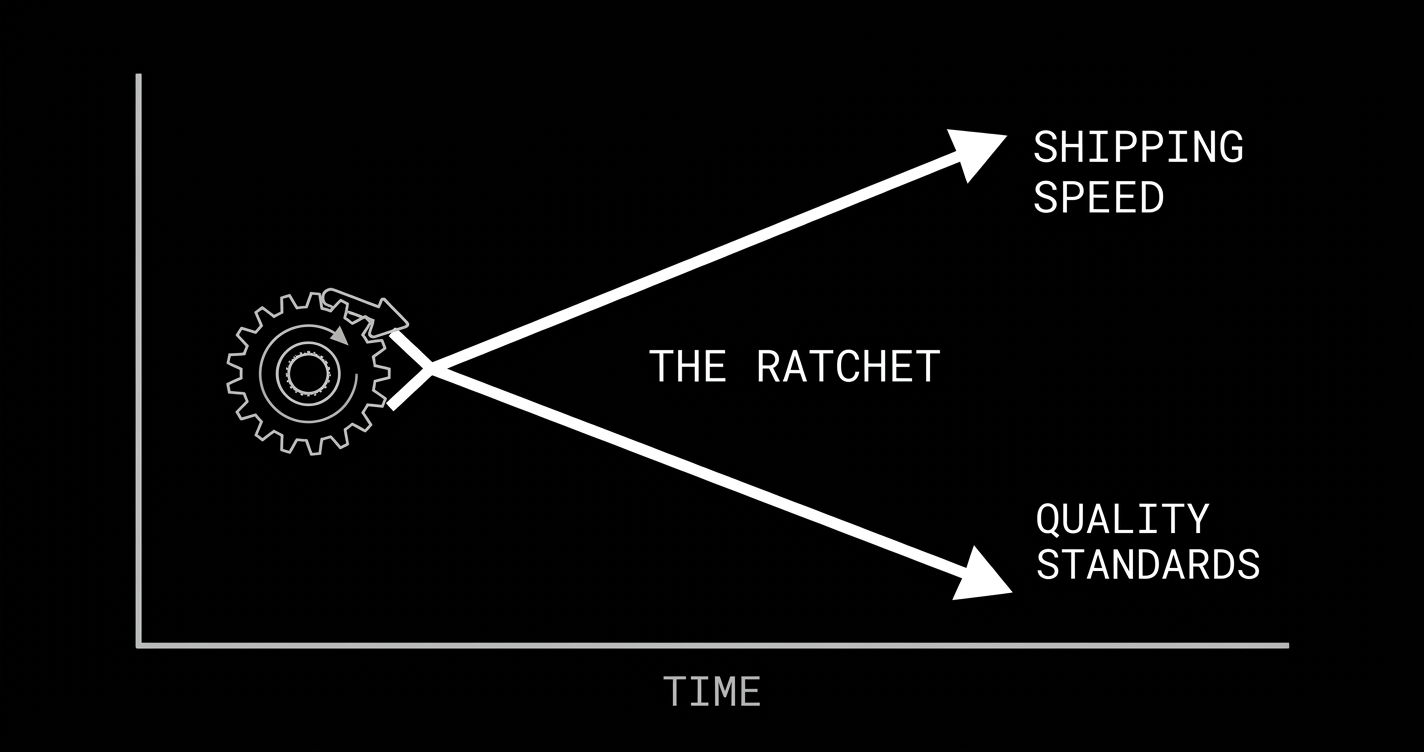
the ratchet only turns one way. no company looks at their competitor's 3x shipping speed and says "we should slow down to understand our code better." they say "we should adopt AI coding tools to keep up." this adds more cognitive debt to the industry-wide balance sheet. the aggregate understanding of the software running the world is decreasing even as the aggregate volume of that software increases.
what nobody is pricing in
the commercial real estate market spent a decade building on the assumption that office occupancy would remain at pre-2020 levels. developers, investors, and cities made trillion-dollar decisions based on this assumption. when it broke, the correction wasn't gradual — it was a cliff. valuations dropped 40-60% in major markets. the assumption was so deeply embedded that the entire financial structure depended on it being true.
the AI-assisted software industry is building on an analogous assumption: that the cost of understanding software will eventually drop to match the cost of generating it. that models will get good enough to verify their own output. that the cognitive debt problem will solve itself as the tools improve.
maybe it will. models are genuinely improving. better context windows, better reasoning, better tool use. each generation is more capable than the last.
but understanding is a property of humans, not of code. you can generate code faster with better models. you cannot generate human understanding faster. understanding requires someone to hold a mental model of what the system does, why it does it that way, and what happens when conditions change. that mental model lives in human brains, accumulates at human speeds, and is permanently lost when the humans who hold it leave the company.
the gap between generation speed and comprehension speed is not closing. it's widening. every improvement in code generation makes it possible to produce more code per unit of human understanding. the ratio of code-to-comprehension is increasing monotonically.
and here's the part that should concern you: nobody is measuring this ratio. there is no dashboard, no metric, no quarterly report that tracks "percentage of codebase the team can confidently explain." the liability is accumulating in the dark.
when the correction comes — when companies discover that they can't modify, secure, scale, or audit systems that nobody understands — it won't announce itself gradually. it will arrive the way the commercial real estate correction arrived: all at once, larger than anyone expected, because the accounting never reflected the true cost of what was borrowed.
the $200 feature didn't cost $200.
it cost $200 to generate and $0 to not understand. the understanding was always the expensive part. we just didn't notice, because in the old economics, the act of building forced the understanding to happen as a side effect. building was slow enough that comprehension could keep up.
that's no longer true. and the bill is accumulating.